Server Issues Understanding, Troubleshooting, and Prevention
Server issues represent a significant challenge for businesses and individuals alike. From minor inconveniences to catastrophic data loss, the impact of server problems can be far-reaching, affecting everything from website accessibility to crucial business operations. Understanding the various causes, troubleshooting techniques, and preventative measures is paramount to maintaining a stable and secure digital environment. This exploration delves into the complexities of server issues, providing practical strategies for mitigation and recovery.
This guide offers a comprehensive overview of server issues, covering their definitions, common causes, effective troubleshooting methods, and proactive prevention strategies. We’ll examine the impact these issues have on users and businesses, explore various recovery methods, and provide illustrative examples to solidify understanding. By the end, you’ll possess a more robust understanding of how to navigate and resolve server-related challenges.
Defining Server Issues
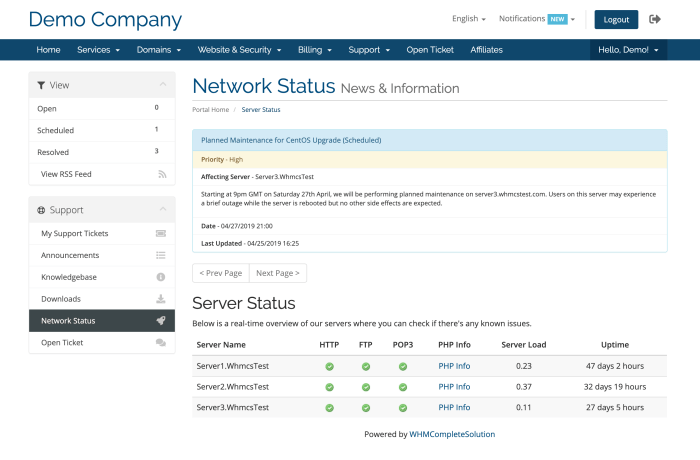
Server issues represent a broad range of problems that can affect the functionality and availability of a server, impacting everything from individual users to entire businesses. These issues vary widely in their nature, severity, and the resulting consequences. Understanding the different types of server issues is crucial for effective troubleshooting and preventative measures.
Server issues can be categorized into several key areas, each with its own set of causes and effects. These categories are interconnected, and a problem in one area can often trigger issues in others.
Hardware Failures
Hardware failures are physical problems with the server’s components. This could include hard drive crashes, RAM failures, power supply issues, or problems with the server’s motherboard or CPU. The impact of a hardware failure depends on the affected component and its criticality to the server’s operation. A failing hard drive might lead to data loss, while a power supply failure could cause a complete system shutdown. Regular hardware maintenance, including preventative checks and component replacements, can significantly mitigate the risk of hardware failures. For example, a RAID configuration can protect against data loss from a single hard drive failure by mirroring data across multiple drives.
Software Glitches
Software glitches encompass a wide spectrum of problems related to the server’s operating system, applications, and software configurations. These can range from minor bugs causing temporary disruptions to critical errors leading to complete system instability. Examples include software conflicts, corrupted files, programming errors, or incompatibility issues between different software components. Regular software updates and patching are vital in preventing software glitches. A poorly configured application, for instance, could lead to performance bottlenecks or unexpected crashes. Robust testing and quality assurance processes during software development are also essential to minimize software-related server issues.
Network Problems
Network problems affect the server’s ability to communicate with other systems and users. These problems can stem from various sources, including network connectivity issues, bandwidth limitations, routing problems, or faulty network hardware (routers, switches, cables). The impact can range from slow response times to complete network outages, preventing users from accessing the server’s services. Network monitoring tools can help identify and diagnose network issues promptly, and proper network design and maintenance are essential for ensuring network stability and reliability. A DDoS attack, for instance, can overwhelm a server’s network capacity, rendering it inaccessible to legitimate users.
Security Breaches
Security breaches involve unauthorized access to the server and its data. This can be caused by various factors, including malware infections, hacking attempts, weak passwords, or vulnerabilities in the server’s software. The consequences of a security breach can be severe, including data theft, financial losses, reputational damage, and legal liabilities. Implementing robust security measures, such as firewalls, intrusion detection systems, and regular security audits, is vital in preventing security breaches. A successful ransomware attack, for example, can encrypt a company’s data, demanding a ransom for its release, leading to significant financial losses and operational disruptions.
Common Causes of Server Issues

Server downtime and performance issues can stem from a variety of sources, impacting everything from website accessibility to critical business applications. Understanding the root causes is crucial for effective mitigation and prevention. This section details the most frequent culprits behind server problems, categorized for clarity and actionable insights.
Server issues are multifaceted, originating from both hardware and software components, as well as external threats. A proactive approach, combining preventative maintenance with robust security measures, is essential for maintaining server health and minimizing disruptions.
Hardware Malfunctions
Hardware failures are a significant contributor to server downtime. These failures can range from minor glitches to complete system collapses, often requiring immediate attention and potentially costly repairs or replacements. Examples include hard drive crashes resulting in data loss or inaccessibility, and power supply failures leading to complete server shutdowns. Overheating components can also cause instability and eventual failure. Regular hardware maintenance, including preventative checks and timely replacements of aging components, is key to minimizing these issues.
Software Bugs and Vulnerabilities
Software errors and security vulnerabilities represent another major source of server problems. Bugs in the operating system, applications, or even within the server’s firmware can cause unexpected crashes, performance bottlenecks, or security breaches. Vulnerabilities can be exploited by malicious actors, leading to data theft, system compromise, or denial-of-service attacks. Regular software updates, rigorous testing, and secure coding practices are essential for mitigating these risks. Examples of such vulnerabilities include unpatched operating systems susceptible to known exploits, or outdated applications with known security flaws.
Misconfigurations
Improper server configurations can lead to a wide range of problems, from performance degradation to significant security risks. Incorrect network settings, flawed firewall rules, or inadequate resource allocation can all contribute to server instability or vulnerabilities. For instance, a misconfigured firewall might inadvertently block legitimate traffic, impacting website accessibility, while insufficient memory allocation can lead to application crashes or slowdowns. Careful planning and rigorous testing during server setup and configuration are crucial to avoid these issues.
Attacks
External attacks, such as Distributed Denial-of-Service (DDoS) attacks or hacking attempts, can overwhelm server resources, leading to downtime or data breaches. DDoS attacks flood the server with traffic, rendering it unresponsive to legitimate requests. Hacking attempts exploit vulnerabilities to gain unauthorized access, potentially leading to data theft or malicious code injection. Robust security measures, including firewalls, intrusion detection systems, and regular security audits, are essential for protecting servers from these threats.
| Cause | Description | Impact | Mitigation Strategy |
|---|---|---|---|
| Hardware Malfunctions | Failures in physical components like hard drives, power supplies, or RAM. | Data loss, server downtime, performance degradation. | Regular hardware maintenance, redundancy (e.g., RAID), preventative monitoring. |
| Software Bugs and Vulnerabilities | Errors in code or security weaknesses in operating systems, applications, or firmware. | System crashes, security breaches, data theft, performance issues. | Regular software updates, penetration testing, secure coding practices. |
| Misconfigurations | Incorrect settings in server configurations, network settings, or security policies. | Performance degradation, security vulnerabilities, service disruptions. | Thorough testing during configuration, adherence to best practices, regular audits. |
| Attacks | Malicious attempts to compromise server security, such as DDoS attacks or hacking attempts. | Server downtime, data breaches, service disruptions. | Firewalls, intrusion detection systems, regular security audits, robust security protocols. |
Troubleshooting Server Issues

Effective troubleshooting is crucial for maintaining server uptime and preventing data loss. A systematic approach, combining observation, diagnostic tools, and methodical investigation, is key to resolving server problems efficiently. This section Artikels a structured process for identifying and resolving common server issues.
Identifying Symptoms and Gathering Diagnostic Information
The initial step involves accurately identifying the symptoms of the server problem. This could manifest as slow response times, complete unavailability, error messages displayed to users, or unusual resource consumption. Gathering diagnostic information is equally important. This includes collecting relevant logs from the operating system and applications, noting the time the issue started, and documenting any changes made to the server configuration prior to the problem’s occurrence. For example, a sudden spike in CPU usage, accompanied by application errors logged at the same time, points towards a software issue rather than a hardware failure.
A Structured Approach to Diagnosing Server Problems
A structured approach significantly improves troubleshooting efficiency. This involves a series of checks and analyses. First, examine server logs for error messages, warnings, or unusual activity. Next, monitor key performance metrics such as CPU utilization, memory usage, disk I/O, and network traffic. Tools like system monitors (e.g., `top` on Linux, Task Manager on Windows) and dedicated monitoring systems (e.g., Nagios, Zabbix) provide real-time insights into server performance. Finally, utilize diagnostic tools specific to the operating system and applications running on the server. These tools can provide detailed information about system processes, network connections, and file system activity. For instance, analyzing network packets using tcpdump can pinpoint network connectivity issues.
Isolating the Root Cause of a Server Issue
Isolating the root cause often requires a systematic elimination process. Start by considering the simplest explanations first, such as network connectivity problems or application misconfigurations. Then, gradually investigate more complex issues, such as hardware failures or software bugs. Thorough investigation is crucial; jumping to conclusions without sufficient evidence can lead to wasted time and ineffective solutions. For example, if slow response times are observed, initially check network latency, then examine CPU and disk I/O before suspecting a database performance bottleneck. A methodical approach ensures that all potential causes are considered and ruled out before determining the root cause.
Troubleshooting Flowchart for Common Server Problems
The following flowchart visually represents a typical troubleshooting process:
Start –> Identify Symptoms & Gather Information –> Check Server Logs –> Monitor Performance Metrics –> Utilize Diagnostic Tools –> Isolate Root Cause –> Implement Solution –> Verify Solution –> End
This flowchart simplifies the process, highlighting the sequential steps involved in effectively troubleshooting server problems. Each step requires careful consideration and appropriate actions based on the specific situation. For instance, if checking server logs reveals a specific error message related to a particular application, the next step would be to investigate that application’s configuration and logs more closely. Conversely, if performance metrics show high disk I/O, the investigation would focus on disk space usage, disk performance, and potential bottlenecks.
Preventing Server Issues

Proactive measures are crucial for maintaining server stability and minimizing disruptions. By implementing a robust preventative strategy, organizations can significantly reduce the frequency and severity of server issues, leading to improved uptime and operational efficiency. This involves a multi-faceted approach encompassing regular maintenance, software updates, security protocols, and comprehensive backup and recovery plans.
Regular maintenance, software updates, and security patches are fundamental to preventing server issues. Neglecting these aspects can leave servers vulnerable to exploits and malfunctions. A well-defined maintenance schedule ensures that potential problems are addressed before they escalate into major outages.
Regular Server Maintenance
Implementing a proactive maintenance schedule is paramount for preventing server issues. This involves a combination of preventative measures and routine checks to ensure optimal performance and stability. A comprehensive maintenance plan should include regular checks of system logs for errors and warnings, updates to operating systems and applications, and the monitoring of resource utilization (CPU, memory, disk space). Ignoring these tasks can lead to performance degradation, security vulnerabilities, and ultimately, server failure.
Software Updates and Security Patches
Software updates frequently include critical bug fixes and security patches that address known vulnerabilities. Failing to apply these updates exposes servers to potential exploits, malware infections, and data breaches. A robust update management system should be in place to ensure timely application of updates across all server components. Prioritizing security patches is particularly crucial, as these often address critical vulnerabilities that could be exploited by malicious actors. For example, a timely update to a web server’s software could prevent a successful cross-site scripting (XSS) attack.
Robust Backup and Disaster Recovery
Data loss can have catastrophic consequences for any organization. Implementing a robust backup and disaster recovery (DR) plan is therefore essential. This involves regularly backing up critical data to an offsite location, ensuring data redundancy and business continuity in case of a server failure or other unforeseen events. The DR plan should detail procedures for restoring data and systems in the event of a disaster, minimizing downtime and data loss. A realistic recovery time objective (RTO) and recovery point objective (RPO) should be defined and regularly tested to ensure the effectiveness of the plan. For instance, a company might aim for an RTO of less than four hours and an RPO of less than 24 hours to ensure minimal disruption to operations.
Server Monitoring Tools
Employing server monitoring tools allows for the proactive detection of potential issues before they escalate into major problems. These tools provide real-time insights into server performance, resource utilization, and system health. Early detection of anomalies, such as unusually high CPU usage or disk space depletion, allows for timely intervention, preventing performance degradation or complete failure. Many monitoring tools offer alerts and notifications, enabling administrators to address issues promptly. This proactive approach can significantly reduce downtime and maintain optimal server performance. For example, a monitoring tool might detect a slow database query, allowing the administrator to optimize the query before it impacts overall server performance.
Regular Server Maintenance Checklist
A comprehensive checklist ensures consistent and thorough server maintenance. This checklist provides a framework for routine tasks, but specific tasks and frequencies may need adjustment based on individual server configurations and usage patterns.
| Task | Frequency | Notes |
|---|---|---|
| Review system logs for errors and warnings | Daily | Identify and address potential issues promptly. |
| Check CPU, memory, and disk space utilization | Daily | Monitor resource usage to identify potential bottlenecks. |
| Apply operating system and application updates | Weekly | Prioritize security patches. |
| Run backups | Daily/Weekly (depending on criticality of data) | Test backups regularly to ensure data recoverability. |
| Perform security scans | Monthly | Identify and address security vulnerabilities. |
| Review server performance metrics | Weekly | Identify trends and areas for improvement. |
| Perform a full system reboot | Monthly | Clears temporary files and improves stability. |
Server Issue Impact and Recovery

Server issues can significantly disrupt operations, impacting various stakeholders and necessitating swift and effective recovery strategies. The severity of the impact depends on the nature of the issue, its duration, and the preparedness of the organization. A robust recovery plan is crucial for minimizing downtime and maintaining business continuity.
The impact of server issues reverberates across different stakeholders. Users experience disruptions in accessing services, leading to decreased productivity and potential frustration. Administrators face the pressure of resolving the issue quickly and efficiently, often working under significant time constraints and stress. Businesses, meanwhile, can experience financial losses due to downtime, damage to reputation, and potential legal liabilities. The longer a server remains offline, the more severe the consequences become for all involved.
Impacts on Stakeholders
Server outages directly affect user productivity and satisfaction. For instance, an e-commerce website experiencing server issues will prevent customers from making purchases, leading to lost revenue and potential damage to brand reputation. Administrators are responsible for diagnosing the problem, implementing solutions, and managing the recovery process, which can be incredibly demanding. Businesses suffer financial losses due to lost productivity, potential legal repercussions from data breaches (if applicable), and damage to their public image. The magnitude of the financial impact depends on the nature of the business and the duration of the outage. A small business might face significant hardship from even a short outage, while a larger corporation may experience less proportional impact but still significant financial losses.
Data Restoration Strategies
Effective data restoration is paramount following a server issue. This involves recovering data from backups, ensuring data integrity, and minimizing data loss. Different backup strategies exist, including full backups, incremental backups, and differential backups. The choice of strategy depends on factors such as the frequency of backups, the amount of data, and the recovery time objective (RTO). Data restoration procedures should be thoroughly documented and regularly tested to ensure their effectiveness during an actual outage. A robust backup and recovery system should be in place to facilitate quick restoration, minimizing business disruption. For example, a company using a cloud-based backup system can often restore data more quickly than one relying on local backups.
System Recovery Methods
System recovery involves restoring the server’s operating system, applications, and configurations to a functional state. This can be achieved through various methods, including restoring from backups, using failover systems, and implementing disaster recovery plans. Restoring from backups is a common method, involving restoring the entire server image or individual files from a backup repository. Failover systems automatically switch to a redundant system in case of a primary server failure, minimizing downtime. Disaster recovery plans Artikel procedures for recovering from major incidents, including server failures, natural disasters, or cyberattacks. These plans often involve replicating data to a geographically separate location. Choosing the right method depends on the specific situation and the organization’s risk tolerance. For instance, a financial institution might prioritize a failover system to ensure continuous operation, while a smaller company might rely on backups and a less complex disaster recovery plan.
Communication During Server Issues
Effective communication with stakeholders during server issues is crucial for managing expectations, mitigating negative impacts, and maintaining trust. This involves providing regular updates on the status of the issue, the estimated time of resolution, and any potential workarounds. Transparent and timely communication helps prevent misinformation and reduces anxiety among users and other stakeholders. The communication strategy should be pre-defined as part of the incident response plan. For example, a company might use email, social media, and a website status page to keep stakeholders informed. A well-defined communication protocol ensures consistency and accuracy in the information provided.
Incident Response Plan
A well-defined incident response plan is essential for handling server issues effectively and minimizing their impact. The plan should Artikel clear procedures for identifying, responding to, and recovering from server issues.
- Incident Identification and Reporting: Establish clear procedures for reporting server issues, including escalation paths and contact information.
- Initial Response: Define initial steps to be taken upon detection of a server issue, such as isolating the affected system and assessing the impact.
- Problem Diagnosis and Resolution: Artikel steps for diagnosing the root cause of the issue and implementing appropriate solutions.
- Communication and Escalation: Establish communication protocols for keeping stakeholders informed and escalating the issue to appropriate personnel if necessary.
- Recovery and Restoration: Detail procedures for restoring data, systems, and applications to a functional state.
- Post-Incident Review: Conduct a post-incident review to identify areas for improvement in the incident response plan and overall IT infrastructure.
Illustrative Examples of Server Issues
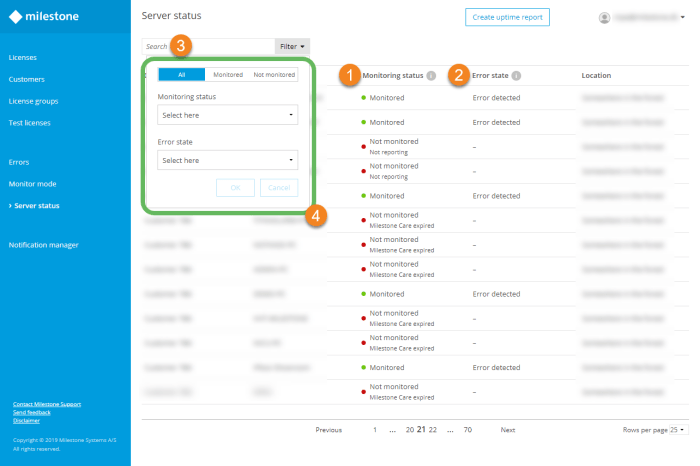
Understanding server issues requires examining real-world scenarios. The following examples illustrate diverse problems, their root causes, observable symptoms, and effective resolution strategies. Each example highlights the importance of proactive monitoring and preventative measures.
Database Server Crash Due to Hardware Failure
A critical database server, responsible for managing millions of customer records for a major e-commerce platform, experienced a complete crash. The cause was identified as a failing hard drive within the server’s RAID array. The symptoms included immediate unavailability of the e-commerce website, error messages indicating database connection failures, and a complete loss of access to customer data. Resolution involved an immediate switch to a redundant server instance (a failover mechanism), followed by a thorough hardware replacement and data recovery from backups. The incident highlighted the critical need for robust backup and recovery strategies, as well as regular hardware maintenance.
Image Caption: A darkened server room, with a single blinking red light on a server rack indicating a critical system failure. Technicians surround the malfunctioning server, working under pressure to restore functionality.
Web Server Attack Leading to Denial-of-Service Condition
A popular social media platform suffered a Distributed Denial-of-Service (DDoS) attack. Malicious actors flooded the platform’s web servers with an overwhelming volume of traffic from multiple sources, rendering the site inaccessible to legitimate users. The symptoms included extremely slow loading times, intermittent connectivity, and ultimately, complete website unavailability. Resolution involved implementing a combination of mitigation techniques, including rate limiting, traffic filtering, and leveraging a cloud-based DDoS protection service. The attack underscored the importance of proactive security measures, such as implementing web application firewalls (WAFs) and having robust DDoS mitigation plans in place.
Image Caption: A graphical representation of a DDoS attack, showing numerous arrows targeting a single server, overwhelming its capacity. The server is depicted as overloaded and struggling to function.
Server Performance Bottleneck Due to Inefficient Code
A company’s internal file-sharing server experienced significant performance degradation. The root cause was identified as inefficiently written code in the server-side application handling file uploads and downloads. The symptoms included extremely slow upload and download speeds, high CPU utilization on the server, and frequent application crashes. Resolution involved optimizing the server-side code, improving database queries, and implementing caching mechanisms to reduce the load on the server. This example demonstrates the importance of well-written, optimized code and regular performance testing to prevent bottlenecks and maintain optimal server performance.
Image Caption: A visual representation of a server’s CPU usage graph spiking dramatically, indicating a performance bottleneck. The graph shows a sharp increase in resource consumption, exceeding the server’s capacity.
Outcome Summary

Successfully managing server issues requires a proactive and multi-faceted approach. Regular maintenance, robust monitoring, and well-defined incident response plans are crucial for minimizing downtime and data loss. By understanding the common causes, implementing effective troubleshooting strategies, and prioritizing preventative measures, individuals and businesses can significantly reduce their vulnerability to server problems and maintain a consistently reliable digital infrastructure. Proactive planning and a commitment to ongoing maintenance are key to a stable and secure online presence.
General Inquiries
What are the signs of a failing server hard drive?
Signs include slow performance, frequent crashes, error messages, unusual noises from the server, and increased error logs related to disk I/O.
How often should I back up my server data?
The frequency depends on your data’s criticality, but daily or at least weekly backups are recommended. Consider incremental backups for efficiency.
What is a denial-of-service (DoS) attack?
A DoS attack floods a server with traffic, making it unavailable to legitimate users. This can be mitigated through firewalls, rate limiting, and distributed denial-of-service (DDoS) protection services.
How can I improve my server’s performance?
Performance improvements can be achieved through optimizing database queries, caching mechanisms, upgrading hardware, using content delivery networks (CDNs), and regularly updating software.


